
What is OCR and How Does it Work? A Comprehensive Guide to Understand Optical Character Recognition
When it comes to data extraction, you have multiple options, including IDP, OCR, ICR, and more. OCR (Optical Character Recognition) is a widely used technology for extracting data from various types of documents, such as PDFs, scanned images, and Word files. While manual data extraction methods like copy-pasting are still used, they are less reliable and can be time-consuming. In today’s data-driven business landscape, effective data extraction tools have become essential for successful decision-making.
This comprehensive guide delves deep into the world of OCR, exploring its intricacies, applications, benefits, and other aspects. Whether you’re a seasoned tech enthusiast or just starting to explore the possibilities of data extraction, this article will provide you with a thorough understanding of OCR and how it can revolutionize your data management processes.
What is OCR?
OCR is a technology that converts different types of documents, such as scanned papers, PDF files, or images, into editable machine-readable text. In simpler terms, it can extract unstructured data from scanned images, PDFs, and Word files into a structured data format. Imagine a super-efficient assistant who can tirelessly read through piles of documents and convert them into a format your computer can understand.
Consider this scenario: you have a mountain of invoices in various formats – some are printed, some are handwritten, and others are even photographs of documents. Manually entering all that data into your system would be a logistical nightmare, prone to errors and incredibly time-consuming. OCR simplifies this process by automatically extracting the text from these documents, saving you countless hours and resources.
History of OCR
The history of Optical Character Recognition (OCR) is a fascinating journey that spans over a century, evolving from early mechanical devices to sophisticated artificial intelligence-powered systems. In the early 1900s, pioneers like Emanuel Goldberg envisioned machines that could read characters and convert them into telegraph code, marking the first steps towards OCR. These early efforts focused on specialized tasks like reading specific fonts or recognizing machine-readable characters.
The mid-20th century witnessed significant advancements with the development of electronic computers. Researchers began exploring ways to use computers to analyze images and recognize patterns, laying the foundation for modern OCR technology. Early OCR systems were limited in their capabilities, often struggling to recognize complex fonts, handwritten text, and low-quality images.
However, with the rise of artificial intelligence and machine learning in the late 20th and early 21st centuries, OCR technology experienced a dramatic transformation. Researchers developed sophisticated algorithms that could learn to recognize patterns in text, adapt to different fonts and styles, and even handle handwritten input. These advancements have led to significant improvements in accuracy, speed, and reliability, making OCR a valuable tool in various applications.
Today, OCR technology is widely used in a variety of fields, including data entry, document management, archival research, and accessibility for the visually impaired. From digitizing historical documents to automating invoice processing, OCR plays a crucial role in streamlining workflows and improving efficiency across numerous industries.
As technology continues to evolve, we can expect further advancements in OCR, such as improved accuracy for handwritten text, support for more languages, and integration with other emerging technologies like natural language processing and computer vision. These advancements will further expand the potential of OCR, making it an even more powerful and indispensable tool in the digital age.
How Does OCR Work?
At its core, OCR technology mimics the human process of reading. It analyzes the structure of an image, identifies characters, and then converts them into machine-encoded text. This seemingly simple process involves several intricate steps:
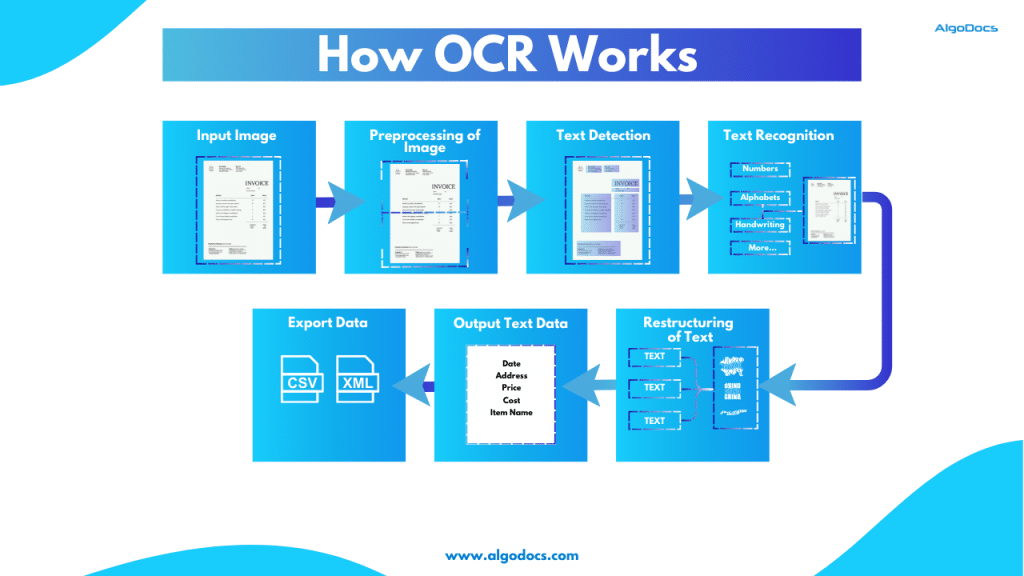
- Image Pre-processing: Before the actual character recognition takes place, the input image is prepared for analysis. This often involves techniques like noise reduction, skew correction, and binarization to remove unwanted artifacts, straighten the image, and enhance contrast.
- Character Segmentation: Once the image is pre-processed, it’s divided into individual characters or glyphs. This step is crucial for accurate recognition, as it isolates each character for subsequent analysis.
- Feature Extraction: In this step, unique features of each character are extracted and analysed. These features might include lines, curves, loops, and other distinguishing characteristics that differentiate one character from another.
- Character Recognition: The extracted features are then compared to a database of known characters. The system uses sophisticated algorithms, often based on machine learning or neural networks, to determine the closest match for each character.
- Post-processing: The recognized text is further refined to correct any errors and improve accuracy. This may involve using dictionaries, contextual analysis, grammatical rules, or even machine learning algorithms to identify and correct misspellings, incorrect spacing, or other inconsistencies.
The Benefits of OCR
OCR offers a multitude of benefits across various industries and applications, but here are some of the essential benefits that suit all industry and business needs:
- Improved Efficiency: OCR automates data entry, eliminating the need for manual input and freeing up valuable time and resources that can be redirected to more strategic tasks. This eventually improves work efficiency and allows you to focus on more important work.
- Reduced Costs: By automating manual tasks, OCR can significantly reduce labor costs associated with data extraction. This can lead to substantial cost savings, especially for organizations that handle large volumes of documents.
- Enhanced Accuracy: OCR systems can achieve high accuracy rates, minimizing errors associated with manual data extraction. This ensures data integrity and reliability.
- Better Searchability: OCR converts scanned documents and images into searchable text, making it easier to find information within large volumes of data. This can significantly improve information retrieval and knowledge management.
- Improved Data Management: OCR helps organize and manage data more efficiently. By converting unstructured data into structured formats, OCR facilitates data analysis, reporting, and decision-making.
- Preservation of Historical Documents: OCR plays a crucial role in preserving historical documents by converting them into digital formats, ensuring their longevity and accessibility for future generations.
- Data Security: Data security is very important for any organization. Access to sensitive data by unauthorized persons can lead to many security concerns. With OCR technology, your data is secured within the application, and only authorized individuals within your organization or team can access this valuable data.
How to Use OCR for Data Extraction
Using OCR for data extraction is surprisingly straightforward. There are numerous OCR tools available, ranging from free online services to sophisticated software solutions. Here’s a general workflow:
- Choose an OCR Tool: Select an OCR tool that meets your needs and budget. Consider factors like accuracy, supported languages, output formats, features, and pricing.
- Prepare Your Document: Ensure your document is clear and legible. If necessary, enhance the image quality before processing. This might involve adjusting brightness, contrast, and sharpness, or using image editing tools to remove noise or correct skew.
- Process the Document: Upload your document to the OCR tool and initiate the recognition process. Most tools offer a simple interface for uploading files and configuring settings like language selection and output format.
- Verify and Edit: Review the extracted text for any errors. Most OCR tools allow you to edit the output before saving it. This is an important step to ensure data accuracy and completeness.
- Save and Export: Save the extracted text in your desired format, such as a Word document, Excel spreadsheet, or plain text file. Many OCR tools offer various export options and integrations with other applications.
OCR Use Cases: Real-World Applications
OCR is not just a theoretical concept; it’s a powerful technology with real-world applications across diverse industries:

Algodocs is an AI data extraction tool that uses AI and OCR technologies to extract data from documents. You can sign up for a free-forever plan and access all the premium features for free.
- Healthcare: OCR is transforming the healthcare industry by digitizing patient records, making them easily accessible to healthcare providers. This improves patient care, streamlines administrative processes, and reduces medical errors.
- Case Study: A large hospital system implemented an OCR solution to digitize millions of patient records, reducing storage costs, improving data accessibility, and enabling faster retrieval of critical information during emergencies.
- Finance: Banks and financial institutions rely heavily on OCR to process checks, invoices, and other financial documents. OCR automates data entry, reduces processing times, and minimizes errors in financial transactions.
- Case Study: A leading bank implemented an OCR system to automate check processing, reducing manual labour by 80% and significantly improving transaction speed and accuracy.
- Legal: Law firms leverage OCR to convert legal documents into searchable and editable formats. This allows lawyers to quickly access relevant information, manage case files efficiently, and streamline legal research.
- Case Study: A law firm used OCR to digitize thousands of legal documents, enabling keyword searches, efficient document management, and improved collaboration among legal teams.
- Education: OCR assists in digitizing textbooks and creating accessible learning materials for students with visual impairments or other disabilities. It also helps educational institutions manage student records and automate administrative tasks.
- Case Study: A university implemented OCR to digitize library archives, making historical documents and rare books accessible to students and researchers online.
- Government: Government agencies use OCR to process forms, applications, and other documents, improving efficiency, reducing paperwork, and enhancing citizen services.
- Case Study: A government agency used OCR to automate the processing of tax forms, reducing manual data entry, improving accuracy, and speeding up tax return processing times.
Choosing the Right OCR Solution
Selecting the right OCR solution depends on your specific needs and requirements. Here are some key factors to consider:
- Accuracy: The accuracy rate of the OCR software is crucial, especially for critical documents. Look for solutions with high accuracy rates and advanced error correction capabilities.
- Supported Languages: Ensure the software supports the languages you need for your document processing. Some OCR solutions specialize in specific languages or character sets.
- Output Formats: Choose a solution that offers output formats compatible with your workflow and applications. Common output formats include plain text, Word documents, Excel spreadsheets, PDF files, and XML.
- Features: Consider additional features like batch processing (processing multiple documents simultaneously), automatic document feeding, zonal OCR (extracting data from specific zones or regions within a document), and integration with other applications like document management systems or databases.
- Deployment Options: OCR solutions can be deployed on-premises, in the cloud, or as a hybrid solution. Consider your infrastructure, security requirements, and scalability needs when choosing a deployment option.
- Cost: OCR solutions range from free online tools to enterprise-grade software with advanced features and support. Choose a solution that fits your budget and provides the necessary functionality.
- Vendor Reputation and Support: Select a reputable vendor with a proven track record in OCR technology. Consider factors like customer support, documentation, and software updates when making your decision.
Delving Deeper: OCR Algorithms and Techniques
While the basic principles of OCR remain consistent, different OCR solutions employ various algorithms and techniques to achieve optimal results. Here’s a closer look at some common OCR approaches:
- Pattern Recognition: This approach involves comparing the scanned image to a library of known character patterns. The system identifies characters by matching their shapes and features to the stored patterns.
- Feature Extraction: This technique focuses on extracting unique features of each character, such as lines, curves, and loops. These features are then used to identify characters based on their distinctive characteristics.
- Neural Networks: Neural networks are a type of machine learning algorithm that can be trained to recognize characters based on a large dataset of labeled images. Neural networks have proven to be highly effective in OCR, especially for complex documents and handwriting recognition.
- Zonal OCR: This technique allows users to define specific zones or regions within a document for data extraction. This is particularly useful for forms or documents with a consistent layout.
- Layout Analysis: Layout analysis algorithms analyze the structure and layout of a document, identifying different elements such as headings, paragraphs, tables, and images. This helps in accurately extracting and organizing information from complex documents.
The Future of OCR: AI and Beyond
OCR technology continues to evolve, driven by advancements in artificial intelligence and machine learning. We can expect to see even more accurate and sophisticated OCR solutions in the future, capable of handling increasingly complex documents and extracting deeper insights. Some key trends include:
- Improved Handwriting Recognition: OCR systems are becoming increasingly adept at recognizing handwritten text, thanks to advancements in machine learning and neural networks. This opens up new possibilities for digitizing handwritten documents and automating tasks that previously required manual input.
- Integration with AI: OCR is being integrated with other AI technologies like natural language processing (NLP) to extract even more meaningful insights from documents. NLP can help understand the context of the text, identify key entities, and extract relationships between different pieces of information.
- Cloud-Based OCR: Cloud-based OCR solutions offer scalability, accessibility, and cost-effectiveness, making them ideal for businesses of all sizes. Cloud OCR services provide on-demand access to powerful OCR engines without the need for on-premises infrastructure.
- Mobile OCR: Mobile OCR applications are becoming increasingly popular, allowing users to capture text from images using their smartphones or tablets. This enables on-the-go data extraction and enhances productivity.
- Hyperautomation: OCR is playing a key role in hyperautomation, which combines AI, RPA, and other technologies to automate complex business processes. OCR enables data extraction from various sources, feeding it into automated workflows for efficient processing and decision-making.
Ethical Considerations in OCR
While OCR offers numerous benefits, it’s important to consider the ethical implications of this technology:
- Data Privacy: OCR involves processing sensitive information, such as personal data or confidential documents. It’s crucial to ensure that OCR solutions comply with data privacy regulations and implement appropriate security measures to protect sensitive information.
- Bias in Algorithms: OCR algorithms, especially those based on machine learning, can be susceptible to bias if the training data is not representative or contains biases. This can lead to inaccurate or unfair results, especially in applications like facial recognition or automated decision-making.
- Job Displacement: While OCR can automate tasks and improve efficiency, it can also lead to job displacement in certain sectors. It’s important to address the potential impact on employment and provide opportunities for reskilling and upskilling.
Top 5 OCR Tools (Free and Paid)
- Algodocs: Algodocs is an AI data extraction platform that uses AI, ML and OCR engine to automate the process of extracting structured and instructed data from various types of documents. It can handle various document types, including PDF, Scanned images, and forms, Invoices. Algodocs can be integrated with other business applications for seamless data extraction experience.
Price- Free and Paid
- ABBYY FineReader: Abby is one of the older OCR suites available in the market. This app offers data extraction from various types of documents, such as PDFs, Word documents, and scanned images.
Price- Free and Paid
- Docsumo: Docsumo is an intelligent document processing platform to extract key data from various documents, such as invoices and contracts. Docsumo can be seamlessly integrate with third party apps as well, allowing for streamlined workflows and faster data-driven decision-making.
Price- Free and Paid
- OnlineOCR.net: This free online OCR service supports various file formats and is simple to use with a user-friendly interface. It offers basic OCR functionality with limited customization options, and has limitations on file size and processing speed for free users
Price – Free
- NewOCR.com: NewOCR is a free online OCR service that supports multiple languages and features a simple drag-and-drop interface. It offers basic OCR functionality with limited customization options and may have occasional downtime due to server load.
Price – Free
Conclusion
OCR is a transformative technology that bridges the gap between physical and digital information. By automating data extraction, OCR empowers businesses and individuals to unlock the value hidden within their documents. As OCR technology continues to advance, driven by AI and machine learning, we can expect even more innovative applications and benefits in the years to come.
By understanding the capabilities and limitations of OCR, organizations can leverage this powerful technology to improve efficiency, reduce costs, enhance accuracy, and gain valuable insights from their data. As we move towards a more data-driven world, OCR will play an increasingly important role in unlocking the power of information and driving innovation.
What is the difference between OCR and ICR?
OCR (Optical Character Recognition) focuses on recognizing printed or typed text, while ICR (Intelligent Character Recognition) specializes in recognizing handwritten text. ICR is generally more challenging due to the variability in handwriting styles and requires more sophisticated algorithms to achieve accurate results.
What are some common OCR errors?
OCR errors can occur due to factors like poor image quality, unusual fonts, complex layouts, or handwritten text. Common errors include misidentified characters, incorrect spacing, missing words, and inaccurate formatting.
How can I improve the accuracy of OCR?
To improve OCR accuracy, ensure your documents are clear and legible. Pre-processing techniques like noise reduction, skew correction, and image enhancement can also help. Choosing an OCR solution with high accuracy rates and advanced error correction capabilities is essential.
Is OCR secure?
OCR itself is a secure technology. However, the security of your data depends on the OCR tool you use and how you handle the extracted information. Choose reputable OCR solutions that comply with data privacy regulations and implement appropriate security measures to protect sensitive information.
What is the future of OCR?
OCR technology is constantly evolving, driven by advancements in AI and machine learning. We can expect to see more accurate, efficient, and intelligent OCR solutions in the future, capable of handling even more complex documents and extracting deeper insights. Emerging trends include improved handwriting recognition, integration with AI technologies like NLP, cloud-based OCR, mobile OCR, and hyper automation.
